云端租赁
面向标准化算力需求,线上提供 GPU 超节点资源租赁能力,支持按需申请、统一交付与后续弹性扩展。
按 Token 计费的大模型推理服务,覆盖主流领先的开源模型。兼容 OpenAI、Anthropic API,简单配置即可接入。
支持主流开源模型品牌:MiniMax · Kimi · GLM · Qwen · DeepSeek
主打长上下文与生产力场景,适合文档处理、摘要、多轮业务对话。
多模态、超长上下文与代码类任务稳定,是 Agent 与研发工具链的常用底座。
在中文语料上具备优势,覆盖通用对话、工具使用与智能体工程。
模型线完整,从端侧小模型到旗舰 MoE 均已覆盖,兼顾性能与成本。
在推理、代码与数学任务上有口碑,MoE 路线提供了优秀的性价比。
wylon 新云将持续上线新模型,实际可用模型请以控制台「模型广场」为准。
Token 工厂与 GPU 超节点共享同一套技术底座。通过大模型推理 OS 统筹纵向贯通的存力资源、横向成网的算力资源,让国产 GPU 的能力从单点资源走向系统级推理基础设施。
Token 工厂通过 API 直接提供模型推理服务;
GPU 超节点以算力资源形式提供推理基础设施。
开发者与企业可根据使用和资源需求灵活选择,两者共享同一套系统云底座。
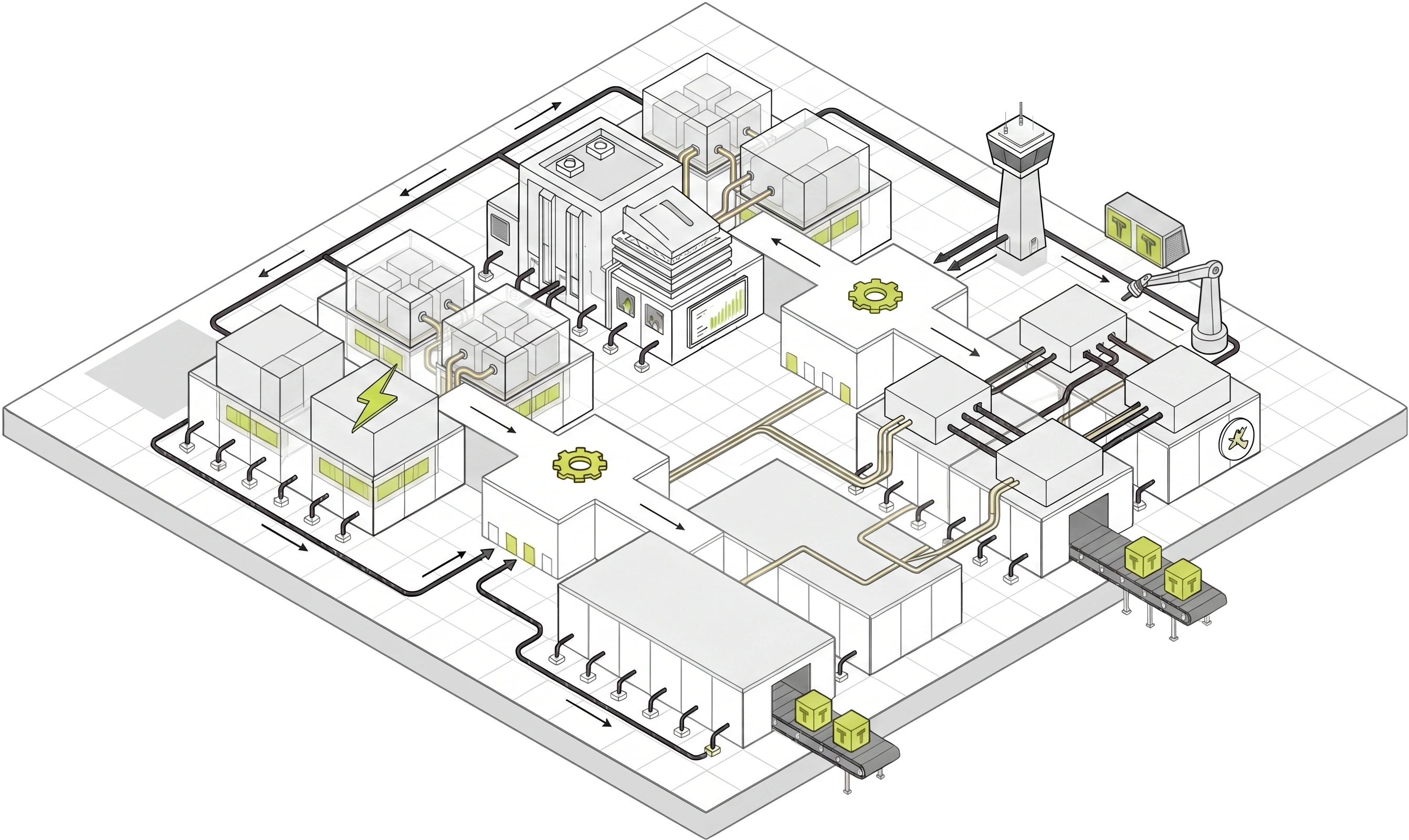
Hiten OS 统筹纵向存力与横向算力,构成面向国产 GPU 的系统级大模型推理底座。
通过统一调度,将纵向贯通的存力与横向成网的算力组织为一套完整运行空间,让模型负载更直接地落到硬件效率上。
围绕上下文、缓存与数据访问需求,打通多层级存力通道,为大模型长上下文和高并发推理提供持续支撑。
通过算力单元之间的高速互联与协同,将分散资源组织为横向计算平面,为大模型推理提供可扩展的并行基础。
卧龙超节点系统能实现提升单用户响应速度的同时保持更高的系统总吞吐,拓展了国产 GPU 在大模型推理场景中的系统效率边界。
从硬件兼容性、超节点系统架构、模型推理引擎到API服务的端到端一体化云化基础设施,提升整合程度,降低性能损耗。
面向生产级负载设计的高可用架构,提供稳定可靠的企业级服务质量保障。
开箱即用的推理API,无需基础设施管理。
依托系统级缓存技术,预填充速度可达常规方案的 10 倍。
wylon新云超节点系统兼容壁仞、沐曦、曦望、寒武纪等品牌。
Token工厂已正式开放注册,几分钟内即可完成集成。