Online Supernode Rental
Online access to GPU Supernode resources with request-based provisioning, unified delivery, and room for future elastic expansion.
A high-performance LLM inference platform built for developers and enterprises.
Pay-per-token inference for leading open-source LLMs. OpenAI- and Anthropic-compatible APIs, ready to use with your existing clients.
Supported model families: MiniMax · Kimi · GLM · Qwen · DeepSeek
Long-context, productivity-grade workloads — document processing, summarization, multi-turn business conversations.
Solid on multimodal, ultra-long context, and code — a popular foundation for agents and developer tooling.
Strong on Chinese corpora — covers general chat, tool use, and agentic workflows.
Full lineup from on-device tiny models to flagship MoEs, balancing performance and cost.
Reputation for reasoning, code, and math — its MoE line offers excellent price-performance.
See the full list, context lengths, and pricing in the model catalog and pricing pages.
wylon continuously adds new models — the authoritative, up-to-date list is the Model Plaza in your console.
GPU compute for online supernode rental and enterprise dedicated service. Now accepting early-access requests.
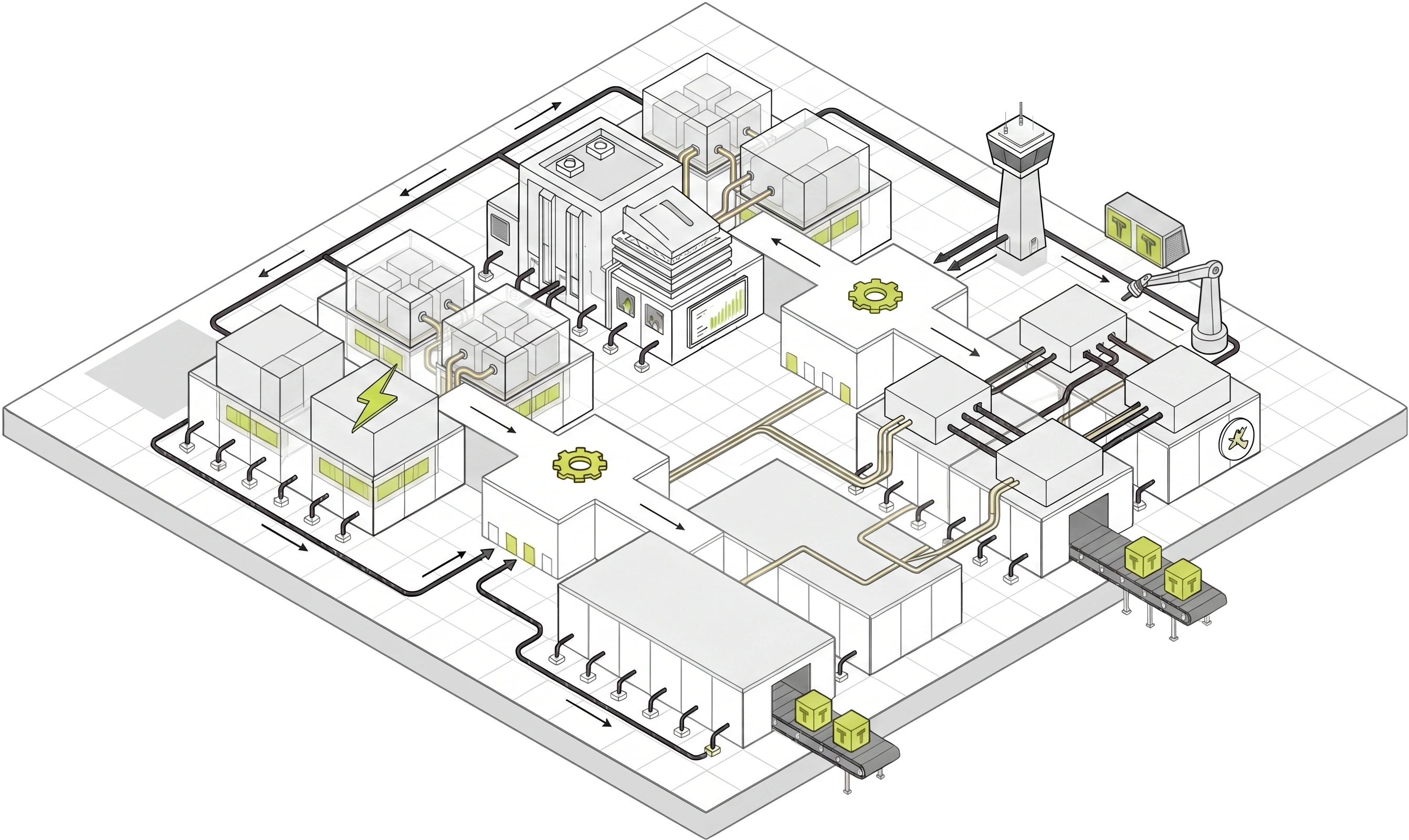
Token Factory and GPU Supernode share the same technology foundation. Through an LLM inference OS that coordinates vertical storage resources and horizontal GPU fabric, wylon turns domestic GPU capacity from isolated resources into system-level inference infrastructure.
Token Factory delivers model inference directly through APIs;
GPU Supernode delivers compute resources for inference infrastructure.
Developers and enterprises can choose by usage pattern and resource needs, while both share the same system foundation.
Hiten OS coordinates vertical storage and horizontal compute to form a system-level LLM inference foundation for domestic GPUs.
Through unified scheduling, Hiten organizes vertically integrated storage and horizontally networked compute into one complete runtime space, allowing model workloads to translate more directly into hardware efficiency.
By connecting context, cache, and data-access layers, the storage plane provides sustained support for long-context and high-concurrency LLM inference.
High-speed interconnects and coordination between GPU units organize distributed resources into a horizontal compute plane for scalable parallel inference.
The wylon Supernode System improves single-user response speed while sustaining higher system throughput, extending the efficiency frontier for domestic GPUs in large-scale model inference scenarios.
End-to-end cloud infrastructure across GPU compatibility, super-node architecture, inference runtime, and API services — tightly integrated to reduce performance overhead.
A high-availability architecture built for production workloads, delivering dependable, enterprise-grade service quality.
Drop-in inference API — no infrastructure to manage.
Backed by system-level caching, prefill is up to 10× faster than baseline implementations.
wylon's super-node system supports Biren, MetaX, Sunrise, Cambricon, and more.
Token Factory is open for sign-ups and can be integrated in minutes.